Introdução ao Git para usuários de TFS/TFVC

Aprender Git pode ser desafiador para desenvolvedores com experiência em versionadores centralizados. Mas não precisa ser assim.
Introdução
O Git está se tornando (já se tornou, muitos diriam) o sistema de controles de versão padrão da nossa área. O versionador foi criado em 2005 por Linus Torvalds para gerenciar o código-fonte do kernel do Linux, e desde então tem apresentado um crescimento fenomenal no seu uso, principalmente após o advento do Github.
Porém, mesmo após uma década de sua existência, alguns mitos sobre esse sistema ainda persistem. Um deles é de que Git é muito difícil de se aprender. E pela experiência que eu tive, isso simplesmente não é verdade.
O Git foi criado com o intuito de oferecer muita flexibilidade e poder aos seus usuários. Ou seja, ele permite uma maior complexidade ou sofisticação. Mas na prática, os comandos básicos, aqueles que você realmente irá usar no dia a dia, são relativamente fáceis de se aprender.
Tendo dito isto, a curva de aprendizado do Git pode apresentar mais desafios para pessoas que estão acostumadas com sistemas de controle de versão centralizados. É natural tentar encontrar padrões e mapear conceitos entre o sistema que se conhece e o que se está aprendendo; mas existem diferenças marcantes o suficiente para que o resultado deste mapeamento seja frustrante.
Com isso em mente, resolvi escrever uma série de artigos para tentar auxiliar desenvolvedores vindos de versionadores centralizados (especificamente TFS/TFVC) e tentando aprender o Git. Não tenho nenhuma pretensão de fazer uma cobertura exaustiva do assunto; muito pelo contrário: nos momentos em que for necessário, indicarei conteúdos que ofereçam uma explicação mais densa de certos tópicos.
Uma nota rápida sobre a nomenclatura utilizada neste artigo
TFS significa Team Foundation Server. É um produto da Microsoft que visa o gerenciamento de projeto, gerenciamento de requisitos, automatização de build, gerenciamento de releases, e diversas outras features.
O TFS também oferece a feature de controle de versão. Desde a versão 2013 existe suporte nativo para o Git, mas antes disso o versionamento era feito por meio de um versionador próprio, conhecido como Team Foundation Version Control (TFVC).
Então, TFS se refere à solução completa de gerenciamento do ciclo de vida da aplicação. E TFVC se refere ao versionador.
Independente disso, neste artigo vou me referir ao versionador como TFS, pois, coloquialmente, muitos desenvolvedores o conhecem por este nome.
Commit != Check-in
O TFS, por ser um versionador centralizado, apresenta um fluxo de trabalho razoavelmente simples, que geralmente consiste em três ações:
- Baixar a versão mais atualizada do código-fonte para sua máquina;
- Efetuar as alterações necessárias;
- Enviar de volta o código com suas alterações para o servidor.
Então, o comando check-in no TFS acaba tendo duas semânticas: a de “salvar” alterações, e “enviar” estas alterações para o servidor.
O que noto é que esta noção de “vou enviar minhas alterações para o servidor” é algo um pouco difícil de esquecer ao se fazer a transição.
Lembre-se: no Git não existe um conceito de servidor central.
O que existe são remotes, ou seja, repositórios remotos. Você pode ter, a princípio, quantos repositórios remotos você quiser. E eles não necessariamente precisam ser tão remotos assim. Sim, eles podem estar em um site como Github/Gitlab/Bitbucket. Mas também podem estar na máquina do colega ao lado, em uma unidade de rede, ou até em uma outra pasta em sua própria máquina.
Quando se trabalha em equipe é comum utilizar-se de um repositório padrão que é considerado, para efeitos de organização, o repositório padrão, onde o código “mais atual” encontra-se. Mais uma vez, no Git não existe conceito de servidor central; o uso de tal repositório padrão é uma convenção utilizada pelos times.
Com isso em mente, vamos treinar um pouco alguns comandos do Git para começarmos a nos habituar com eles. No post de hoje não veremos nada de repositório remoto, servidor, nada disso: apenas comandos locais.
Baixando e instalando o Git
Dizem que houve uma época em que trabalhar com o Git no Windows era problemático. Atualmente, não é mais o caso, como você já vai ver.
Para começar faça o download do Git para Windows.
Clique duas vezes no arquivo baixado, next, next, você sabe. Em geral não deveria haver problema se você deixar todas as opções como default mesmo; no entanto, é interessante fazer uma alteração:
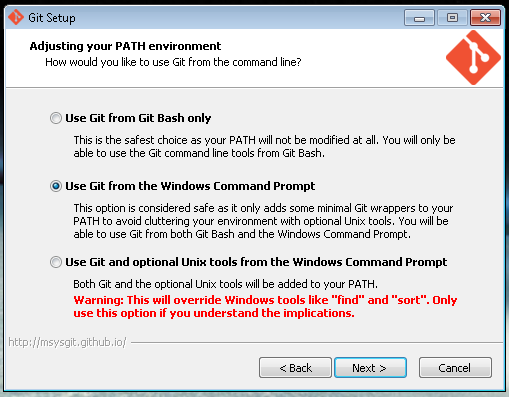
Quando chegar a esta tela, é interessante marcar a segunda opção para que você seja capaz de utilizar o Git a partir do prompt de comando do Windows, e não apenas a partir do Bash do Git.
Configuração básica
Depois de terminada a instalação, é necessária fazer a configuração básica de identidade do Git, que consiste em dizer ao Git seu nome e e-mail para que ele os associe a cada commit que você efetuar.
Para fazer isso, vamos utilizar o Git Bash. No menu iniciar localize o programa “Git Bash” e execute-o. A janela do Git Bash será aberta.
Digite os seguintes comandos:
git config –global user.name “Seu nome”
git config –global user.email “email@exemplo.com”
Existem mais configurações e opções possíveis, mas isso já é suficiente para que você comece a experimentar o Git.
Criando o repositório
No Git Bash, vamos criar uma nova pasta e em seguida acessá-la:
mkdir repo
cd repo
Depois de acessarmos a pasta recém-criada, é hora de criarmos nosso repositório:
git init
Depois de executar esse comando, você verá a seguinte mensagem:
Initialized empty Git repository in C:/Users/your-name/repo/.git/
O prompt do Git Bash deveria estar mostrar algo assim:
Usuario@Maquina MINGW64 ~/repo (master)
Ou seja: usuário logado, localização atual e branch atual. O branch padrão do Git chama-se master. No próximo artigo desta série aprenderemos a operação básica de branches, mas por enquanto vamos permanecer apenas no branch padrão mesmo.
Primeiros comandos
OK, com o repositório criado, é hora de testarmos alguns comandos. Um dos comandos mais úteis e que você irá utilizar com mais frequência é o git status, que serve para visualizar o estado atual em que se encontra o repositório.
Ao executá-lo, você deveria ver a seguinte mensagem:
On branch master
Initial commit
nothing to commit (create/copy files and use “git add” to track)
Ou seja:
- o branch atual;
- que está esperando por seu primeiro commit;
- e indica o que entrará no commit - o que nesse caso é nada, já que ainda não há alterações em nosso repositório.
Ele ainda indica qual é o próximo passo a tomar, i.e. criar ou copiar arquivos e depois usar o comando git add para rastreá-los. Por enquanto, não se preocupe com o que “rastrear” significa, pois isso será abordado no futuro.
Vamos então criar um arquivo.
echo teste > arq1.txt
Execute novamente o comando git status e você verá que desta vez a mensagem está diferente:
Untracked files: (use “git add
..." to include in what will be committed) arq1.txt
nothing added to commit but untracked files present (use “git add” to track)
Alguns conceitos novos, começando por “Untracked files”, ou, em tradução livre, “Arquivos não rastreados”. O Git está vendo o arquivo que acabamos de criar, mas não está pronto ainda para incluí-lo no próximo commit.
O interessante é que mais uma vez o Git nos dá a dica do que precisa ser feito, como você pode ver. Execute o comando:
git add arq1.txt
Execute novamente git status e veja que a resposta mudou novamente:
Changes to be committed:
(use “git rm –cached
..." to unstage) new file: arq1.txt
Por enquanto ignore a mensagem:
use “git rm –cached
..." to unstage
Agora podemos ver que o arquivo adicionado está pronto para entrar no commit. Então, vamos “commitar”:
git commit -m “Primeiro commit”
O comando acima cria o nosso primeiro commit. O parâmetro -m serve para especificar uma mensagem de commit, o que é essencial para o futuro entendimento da evolução de um projeto.
git status novamente:
On branch master
nothing to commit, working directory clean
Para terminar, vamos fazer uma alteração em nosso arquivo. Abra o arquivo no Bloco de Notas (ou outro editor de texto de sua preferência) e acrescente a seguinte linha:
acrescentando uma nova linha
git status novamente:
On branch master Changes not staged for commit: (use “git add
..." to update what will be committed) (use "git checkout -- ..." to discard changes in working directory) modified: arq1.txt
no changes added to commit (use “git add” and/or “git commit -a”)
A mensagem é familiar, apesar de ser diferente das anteriores. Como você já deve estar acostumado, ela termina com uma dica da próxima ação a ser tomada. Vamos então seguir a sugestão do Git:
git add arq1.txt
Perceba que é o mesmo comando que executamos lá atrás, quando o arquivo ainda estava no estado “untracked”. Embora o comando seja o mesmo, neste caso aqui ele tem um significado ligeiramente diferente. No futuro, entenderemos estas diferenças.
Ao executar novamente git status recebemos, novamente, uma nova mensagem:
Changes to be committed: (use “git reset HEAD
..." to unstage) modified: arq1.txt
Embora seja parecida com uma das mensagens anteriores, perceba que agora o nosso arquivo está no estado “modified”, e não “new file”, o que faz bastante sentido.
Imagino que você saiba o que vem a seguir:
git commit -m “Segundo commit: adicionamos segunda linha para testar alteração”
Para terminar, execute novamente o git status e verá novamente a mensagem já familiar: diretório de trabalho limpo, nada a ser commitado.
Conclusão
Este artigo foi extremamente simples, e isso não foi um acidente. Minha intenção foi de mostrar os comandos mais básicos, com a intenção de que você pegue o “feeling” de como se usa o Git.
Perceba que existe um padrão facilmente perceptível nos comandos que executamos:
- cria um arquivo
- “adiciona”
- dá commit
- faz alteração no arquivo
- “adiciona”
- dá commit novamente
- etc
Nos lugares onde coloquei “adiciona”, você sabe que estou me referindo ao comando git add. Você talvez tenha percebido que este comando tem duas finalidades diferentes, evidenciado pelas diferentes mensagens que o git status retornou depois de sua execução.
Você provavelmente também notou os diferentes estados que os arquivos em um repositório podem assumir: “untracked”, “new file”, “modified”. Eles caminham de um estado para o outro, como em uma pipeline.
No próximo post da série vamos nos aprofundar nestas questões. Iremos entender as áreas existentes em um repositório, entender o fluxo de trabalho e os estágios pelos quais os arquivos passam.
Vamos começar também a trabalhar com um dos conceitos mais importantes do Git: branches. Iremos dar início às operações mais comuns que são realizadas com branches, e também mostraremos como branches no Git diferem da maneira que você está acostumado a trabalhar no TFS.
Até lá!
Encontrou algum erro no post? Sugira uma edição ← Escrevendo código bom: como reduzir a carga cognitiva do seu código Funcionalidades do C# 7 que vale a pena conhecer - Parte 2 →